

Snakefooding Python Code For Complexity Visualization
Snakefood is a tool written by Martin Blais to create Python dependency graphs. Combined with GraphViz, snakefood can create beautiful visualizations of Python codebases. Here are graphs for some notable open source projects written in Python.
Python Web Frameworks
The different development philosophies of Bottle, Django, Flask, and Pyramid are apparent by looking at their snakefood graphs.
Bottle
Bottle is a fast and simple micro framework for Python web applications.
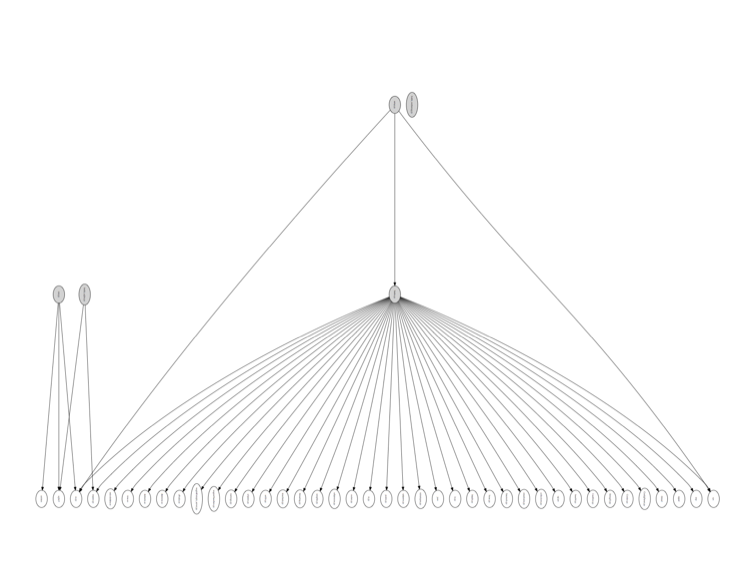
Bottle release 0.12.7
Django
Django is a batteries-included web framework for perfectionists with deadlines.
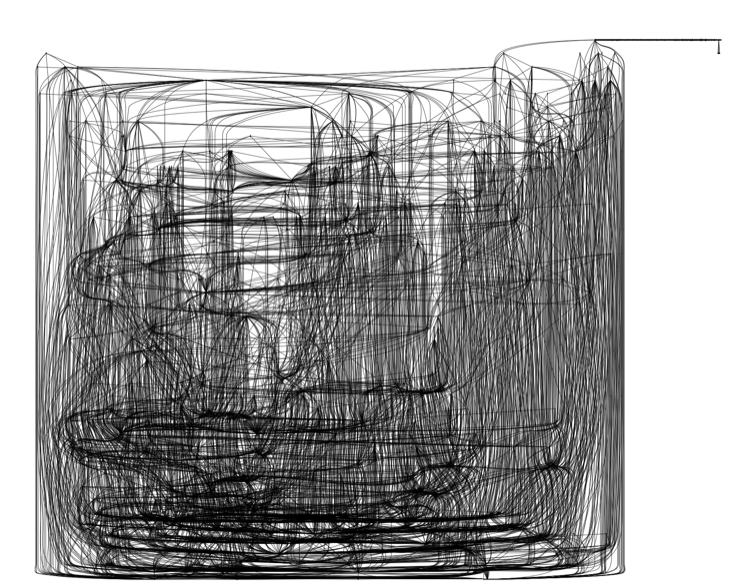
Django release 1.7c3
Flask
Flask is a microframework for Python.
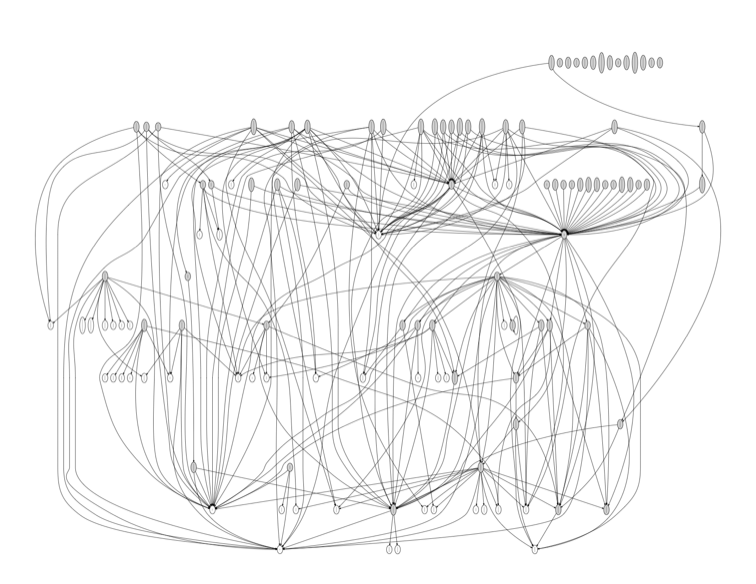
Flask release 0.10.1
Pyramid
Pyramid is a small, fast, down-to-earth, open source Python web framework. It makes real-world web application development and deployment more fun, more predictable, and more productive.
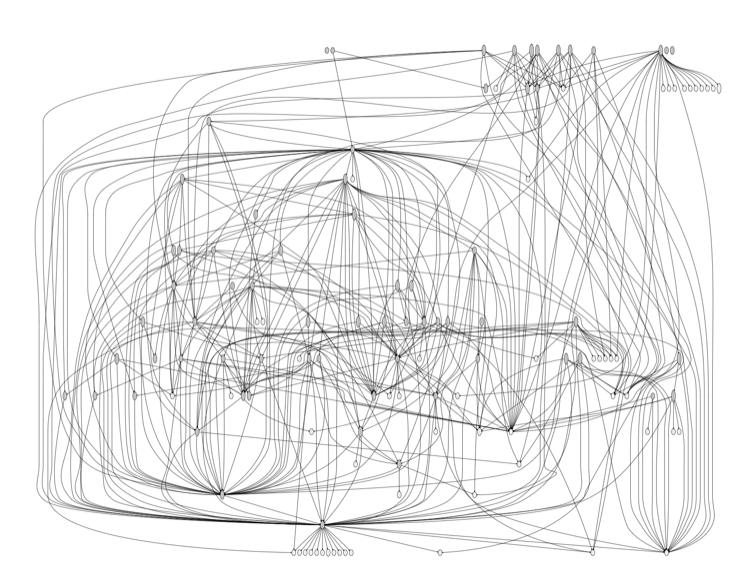
Pyramid release 1.5.1
Queueing Implementations
Hat tip to Sylvain Zimmer for this deck on switching from Celery to RQ which was how I first found out about snakefood.
Celery
Celery is a complex feature-rich distributed queueing implementation.
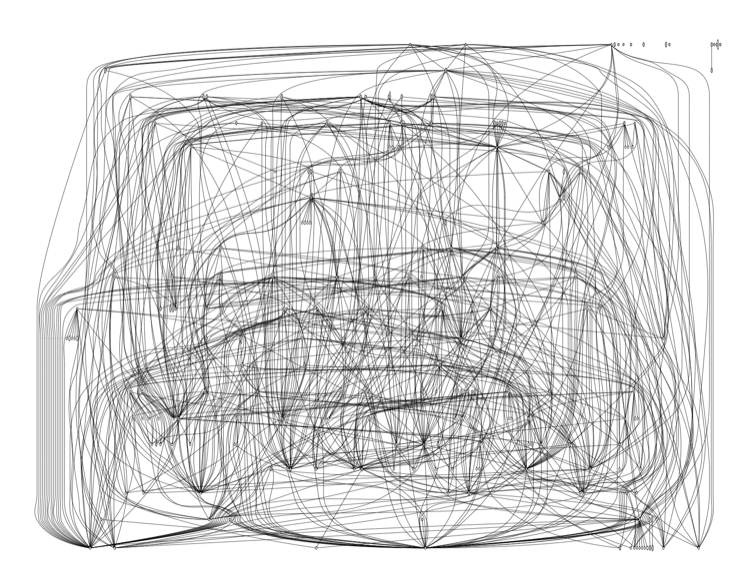
Celery release 3.0.20
RQ
RQ is a simple Python library for queueing jobs and processing them in the background with workers.
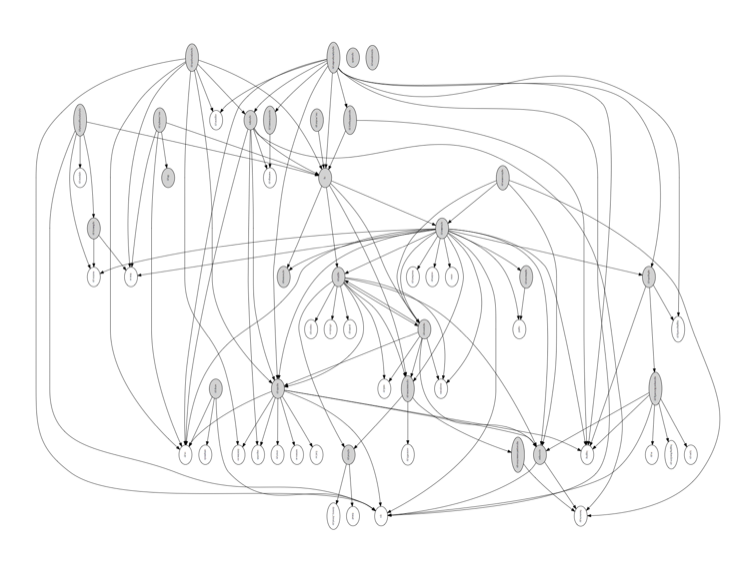
RQ release 0.4.6
Other Python Codebases
For curiosity’s sake I ran snakefood on a few other notable Python codebases.
Twisted
Twisted is an event-based framework for internet applications.

Twisted release 14.0.0
Mercurial
Mercurial is a distributed source control management tool.

Mercurial release 3.1
Requests
Requests is HTTP requests for humans. It is frequently mentioned as an example of an elegant, Pythonic codebase.
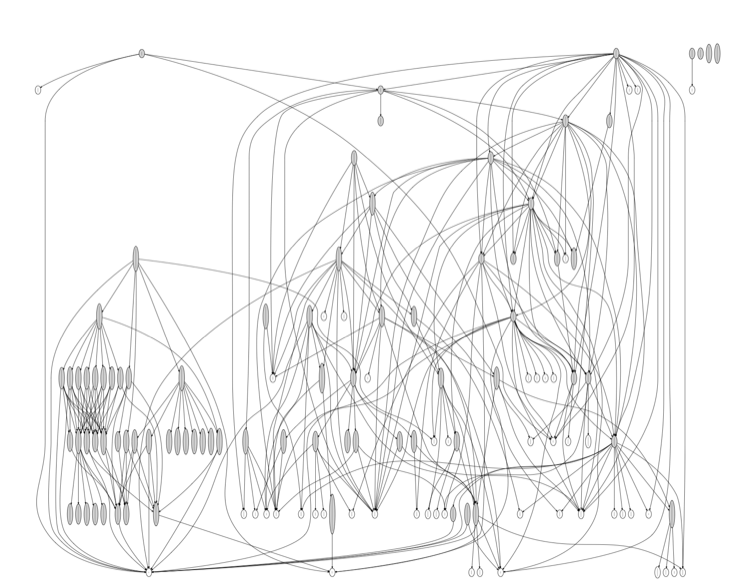
Requests release 2.3.0
IPython
IPython is an alternative to the standard Python shell. If you aren’t using IPython, you should be. Here’s why IPython is awesome.
 IPython release 2.2.0
IPython release 2.2.0
What does this mean?
Snakefood graphs are helpful to visualize both the approximate size of a codebase and the level to which concerns are separated. As a measure of code complexity, snakefood graphs show more information than lines of code (which is not that great of a metric), but at the cost of introducing more room for interpretation than a strictly numeric metric.
The other problem with using snakefood graphs as a measure of code complexity is that it looks at code at the file level. A well-organized codebase containing many small files will look more complex than a codebase with a few very large but extremely long, complex files. Code with high testing coverage also tends to look more complex since the tests are dependent on so many parts of the code. Test and documentation modules were not included in any of the graphs above for this reason.
In cases where a more careful measure of code complexity is required, something like cyclomatic complexity is more appropriate. The graphs created by snakefood are actually similar to what would be used to compute cyclomatic complexity as applied to files instead of functions or classes which is the more usual way to do it.
Instead of using snakefood as a tool for visualizing complexity, the creator of snakefood uses it more to prevent unnecessary dependencies from creeping into the code:
Producing pretty graphs is fun, but I found the most leverage of it when I try to make my code simpler, I generate the graph and inspect unexpected dependencies and try to refactor my code to simply the dependency graph as much as possible (see furius.ca/beancount for a recent example). Enforcing rules can be done by writing a custom script against the snakefood output, as it’s very easy to accidentally introduce unwanted dependencies. I think the result is code that is better organized at a high level. –Martin Blais
So snakefood graphs are are (sometimes) beautiful. They are a fairly quick ad hoc way of visualizing code complexity, and the snakefood output can be used to help identify and enforce dependency relationships. All in all, snakefood is a pretty awesome tool to have in your Python toolbox.
Discussion on
Snakefooding Python Code For Complexity Visualization
by Jess Johnson in Books & Tools
1 Comments
10:45 pm UTC, 2014-09-01Leave a reply